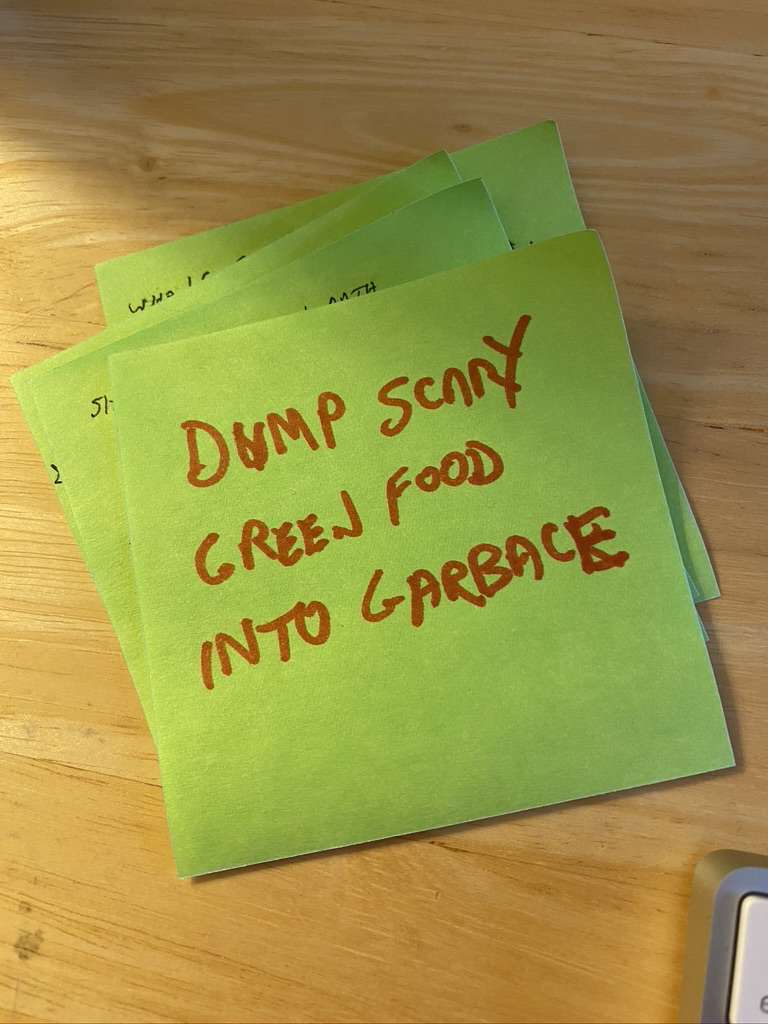Even before NAVSTAR GPS became fully operational, applications like Mapquest, and later, Google Maps could provide us with a least-cost path from one location to another
Cost can be measured in many ways, depending on the type of network we're considering
In a road netwprk, travel distance, travel time, and tolls are some common costs
But they could also include very high costs for
taking the wrong way down a one-way street,
taking a fire truck down a street with a very tight turning radius,
allowing school bus stops that force children to cross busy highways, and so on
What exactly is a network?
Many of the terms we use for discussing pathfinding (and also basic GIS polygon topology) come from graph theory
A graph is a set of nodes (also called points and vertices) connected by edges (also called arcs or links)
Nodes are junctions of some kind
Geographic places, street intersections, communication hubs, airports, etc.
Edges (I like to call them links) show connections between nodes
They might represent streets or other transportation segments, flows of information, etc.
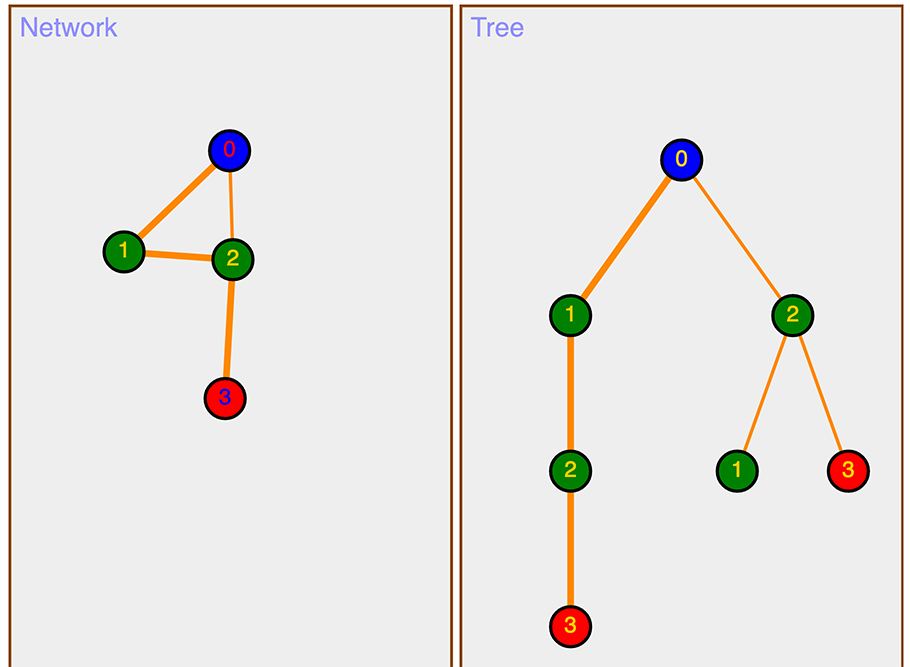
A network is a graph that represents each node and each edge exactly once
A tree is an alternate representation of a network, allowing each node and each edge to be represented multiple times
Trees are often used to simplify pathfinding through a network
In that case, a starting node is put at the top (or root) and all unique paths through the network are represented by their own branch in the tree
In a network, a node can be approached from more than one path
But in a tree, that same network node is represented as many times as it appears in separate paths
Any path you can find in the network from the start to the goal (other than a circular one) is represented as a separate branch of the tree
We will look at 3 network search techniques (algorithms) that use trees to find a path through a network from a starting node to an ending node along the edges in the network
Searching through Networks
Before we look at the search algorithms, the Network Search app below demos the algorithms
It lets you create a network and search for paths from a starting point to a goal
To use the app,
Create nodes by clicking in the Network pane
Create links by dragging between nodes
As you create links to nodes, a tree will start to build in the Tree pane
You can click Select Start or Select Goal to change the starting and ending nodes in the network and tree without creating a new one
The Show Traversal button highlights the nodes that a search algorithm visits when its searching for a path
All possible paths between the start node and the goal node are represented uniquely in the tree
As you read about search types below, try them out in the app
Use the Search Type dropdown to select one
What can a network represent?
We can use networks to explore
transportation paths between geographic places,
flows of information between places,
and an almost unlimited number of other tasks involving connections and flows
Please Note: The positions of nodes in a network do not imply geographic position
Instead, the main purpose of a network is to show how nodes are connected to one another
We can apply whatever attributes we want to nodes, but a network diagram is all about connections
When we talk about finding a path through a network, we're almost always talking about a least-cost or optimal path
where cost can be defined by barriers, impedances, or some other kind of friction obstructing flow between one node and another
These are the paths that navigation apps supply for us
On the other hand, a non-optimal path
may not provide the least cost path between points
So why consider non-optimal paths?
Non-optimal algorithms are easier to understand than optimal algorithms
We'll look at 2 non-optimals first, then move on to an optimal
Non-optimal search techniques: depth-first and breadth-first search
To understand these 2 algorithms, we need to look at 2 simple ways we can create a 'to-do list' in a computer program
It is often much easier to solve a big problem as a bunch of much smaller pieces, much like you would try to do by creating to-do lists.
So if your big problem is to clean the house, you may end up writing a bunch of sticky notes for yourself:
My sticky notes for Cleaning the House
Take out the garbage.
Wash the kitchen floor.
Dump scary green food in the refrigerator into the garbage.
Rake the leaves and put them in bags.
Vacuum the rugs.
If you stick one on top of another, you can rip them off as you complete them
To clean the house:
Take a sticky note from the top, read it, and do the job
Keep removing jobs off the pile until there aren't any more—you're done
Congratulations—you implemented a stack!
A stack is a data structure in which the last item put (or pushed) into the structure is the first item to be removed from it (LIFO--last in, first out)
In our sticky note example, we put "dump scary food..." on the stack last so it will be the first job we encounter when we remove, or pop jobs off the stack
On a stack data structure, you can only push or pop jobs from the same end (in our sticky note example, the top of the pile)
How come? Because this makes them easy and efficient to understand, create and use
Another, very similar data structure, is a queue
A queue is data structure in which the first item put into the structure is the first item to be removed from it (FIFO--first in, first out)
Unlike a stack, you push jobs on one side, and pop them from the other
You may need to click on the following video to start it
There are many ways to create stacks and queues in programs but we won't worry about that here
Just think of them as ways to organize the tasks that a program needs to complete
Non-optimal algorithms for searching networks
Non-optimal paths get you from the start to the goal, but not necessarily by incurring the least-cost
They are sufficient to get from the start to goal but maybe not the best possible path
A non-optimal search may find a least-cost path accidentally, but usually it doesn't, especially in larger networks
Here is the algorithm for our first non-optimal technique: depth-first
To perform depth-first search:
Put the starting node on the empty stack
While the stack is not empty,
Pop a node off the stack
If the node is the goal, stop
Otherwise, expand the node by placing its children on the stack, ordered left to right
Let's work through this with a simple example
We can see from the network and the tree diagrams that there are 2 possible paths from the start to the goal:
0 → 1 → 2 → 3
or
0 → 2 → 3
Don't worry about which one is shorter or faster—depth-first only guarantees to find a path if one exists (not necessarily the least-cost (best) path)
Of all possible start to goal paths, the path that is chosen depends entirely on how the nodes and links in the tree are arranged
Depth-first search uses a stack data structure to organize its work
Important: When you follow the examples in this topic, trace through the tree, not the network
Remember—each branch of the tree is a separate path through the network
In the tree, individual nodes are shown more than once if they occur on more than one path
All the search algorithms here operate on the tree!
Try this out
To replicate this example, follow these steps in Network Search
Make sure Depth First is the selected Search Type in the drop down list
In the app, click to create the nodes as you see them in this example (make sure that the Create Node button is selected)
When you drag the links between your nodes, use the following order:
0 → 1
1 → 2
0 → 2
2 → 3
Other orders will work too (try them), but this one will create a tree identical to the example (to keep things easier for you to follow)
When you finish your network, try clicking the Show Traversal button—it will flash the nodes that the search inspected on its way toward finding a path to the goal
And now, using sticky notes, here we go!
Put the starting node on the empty stack
Ok, Node 0, the starting node, is now on the stack
While the stack is not empty
The stack has one item on it so we keep going
Pop a node off the stack
We look at the item that we popped off the stack
If the node is the goal, stop
Nope, it's not the goal node, so we move on to the next step...
Otherwise, expand the node by placing its children on the stack, ordered left to right
In the tree, we see that the children of node 0 are 1 and 2
I put the nodes on the stack so that node 2 goes on before node 1 (because 1 is left-most child of 0 in the tree)
And now we go back up to the While statement...
While the stack is not empty,
There are 2 node on the stack now
Pop a node off the stack
We look at the item that we popped off the stack
If the node is the goal, stop
Nope, node 1 is not the goal node
Otherwise, expand the node by placing its children on the stack, ordered left to right
Node 1 has only 1 child—node 2
We put node 2 on the stack
But wait! Isn't node 2 already on the stack?
Yes—It is (at the bottom), but as part of the path that goes directly from node 0 to node 2
Right now, we're expanding the path that goes from node 1 to node 2
Going back to the top of the while loop, the stack is not empty so we pop off node 2
Rememer, this is part of the path that has gone from 0 to 1 to 2
If the node is the goal, stop
No, its not
Otherwise, expand the node by placing its children on the stack, ordered left to right
Node 2 only has 1 child—node 3
We push node 3 onto the stack
And back at the top of the while loop, we see that the stack is still not empty, so...
Pop a node off the stack
And it's the goal node, so we stop!
It's easy to reconstruct the path to the goal node by tracing upward (there's no branching going up—only down)
Who needs a fancy computer when you've got sticky notes?
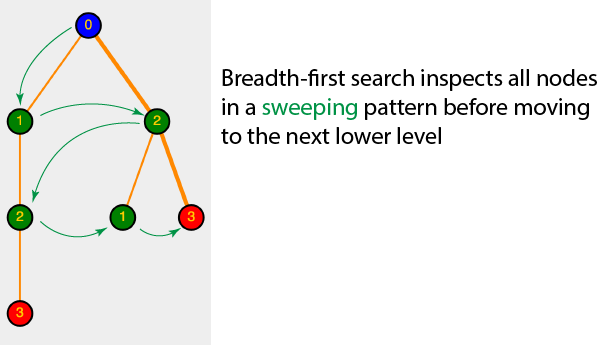
And now for breadth-first search
The only difference from depth-first is that breadth-first uses a queue instead of a stack
This creates a left to right sweeping search pattern across a level of a tree before descending to the next level
To perform breadth-first search:
Put the starting node on the empty queue
While the queue is not empty,
Pop a node off the queue
If the node is the goal, stop
Otherwise, put the children of the node at the back of the queue, ordered left to right
To try this out, remember to set the Search Type to Breadth First
Here's how the search works on our search tree:
An algorithm that gives you optimal paths—branch and bound
You might think that finding an optimal path to the goal would require you to search all possible paths in the network
For large street networks, the time to do so would grow exponentially with the number of nodes
So instead, we guide our search by making good guesses on the way
If you're at a node in a street network, and you only know that
turning left leads to a node with a 15 km straigh-line distance to the goal, and
continuing straight leads to another node with a 25 km straight-line distance to the goal,
Your informed guess would be that turning left will lead to a shorter path to the goal
That's probably right most of the time, but it's easy to think of situations like this:
Although the straight line distance from node 1 to the goal is shorter than the distance of node 2 to the goal, we find a river blocking the way
But if we're working our way through a network by only knowing straight line distances, that may be the best guess we have for proceeding
Straight line distances are easy to determine if we know the 2D grid coordinates of our nodes—just compute the distance by applying the Pythagorean theorem
These guessing strategies are called heuristics
Branch and bound search uses 2 heuristics to guide search
Remaining straight-line distance from a node and
Distance traveled so far on a partial path
A partial path is composed of
nodes (starting from the root and continuing to whichever node is currently at the partial path's end),
actual cost, determined by adding up the costs of traversing its links
If the links are streets, the cost would likely be total travel distance or time so far
Branch and bound uses a sorted stack data structure
The least-cost partial path will always be the next one to be popped
Here is how branch and bound works
To perform branch and bound search,
Make a new partial path that only includes the starting node and has 0 cost. Push the partial path onto the stack.
While there are partial paths on the stack,
Pop a partial path. If the partial path is a complete path to the goal, stop.
If not, expand the node at the end of the partial path, make new partial paths to its children, and push the new partial paths onto the stack.
Sort the partial path stack by combined distance (the straight line distance to the goal plus distance travelled so far) so that the shortest partial path is at the top.
Obviously, there are some programming details that are left unsaid, but this is the big idea:
Keep switching between partial paths so that the one you're expanding has the smallest sum of
the distance travelled so far along the partial paths, and
the estimated distance to the goal (using a straight line guess or some other heuristic)
A branch and bound examples to try out
Try drawing this and then change which node is the start and the goal
Do you always get the shortest path?
I hope so—let me know if you find a bug!
There are many enhancements to branch and bound search that improve its search speed but most share this structure
If you enjoy working on these kinds of problems, you may find it interesting to know that this area was once considered a key part of artificial intelligence research (autonomous navigation through networks)